Hardening ChatGPT Atlas Against Persistent Prompt Injection Threats
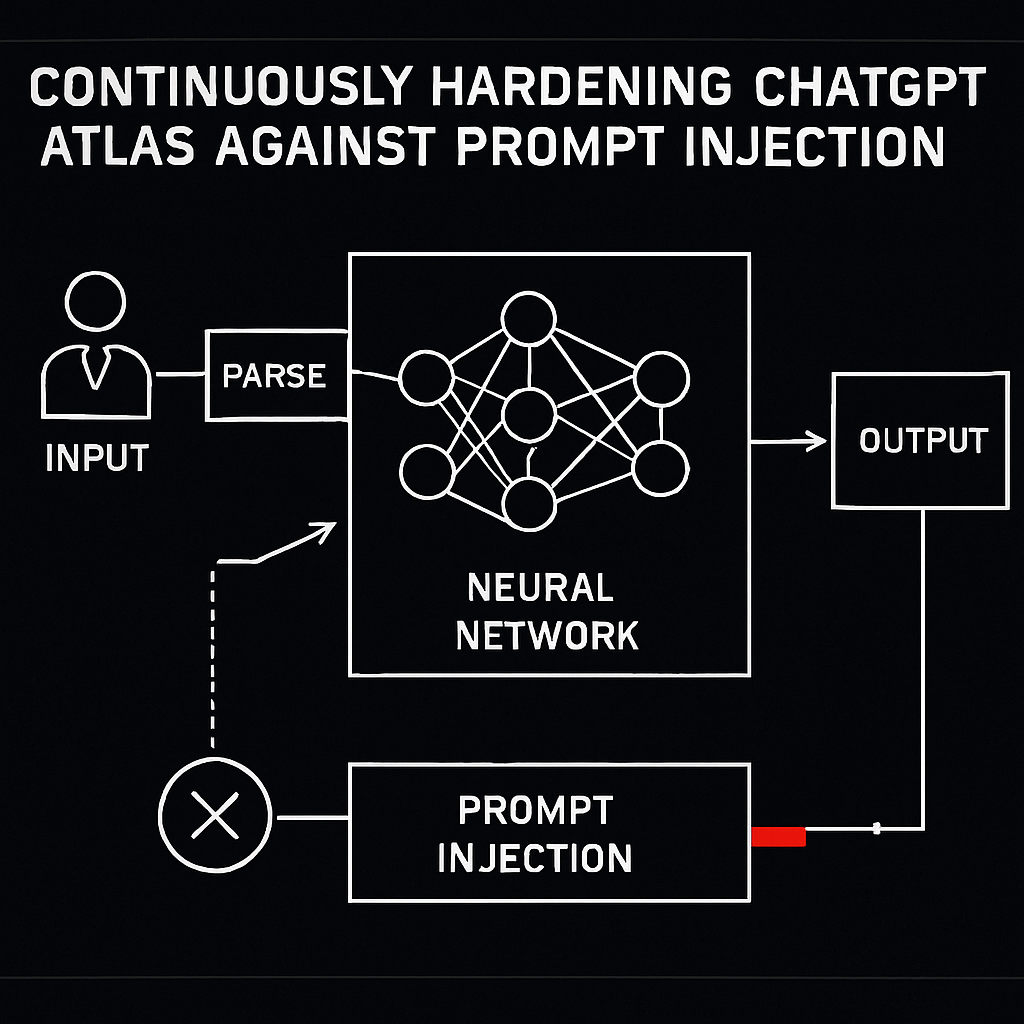
OpenAI is actively enhancing the security posture of ChatGPT Atlas, particularly against the growing threat of prompt injection attacks. Leveraging automated red teaming infused with reinforcement learning, OpenAI has devised a proactive “discover-and-patch” mechanism that continuously identifies and mitigates novel vulnerabilities. This real-time adjustment is critical as it aims to automate defense mechanisms rather than react to external exploit attempts. Despite these advancements, OpenAI acknowledges that AI models with autonomous functionalities, like Atlas, may perpetually remain susceptible to prompt injection. The reality of AI systems being continually vulnerable underscores the necessity for rigorous security measures. OpenAI's approach includes deploying an "LLM-based automated attacker" to simulate and assess potential exploitation scenarios, enhancing the overall resilience of the system.
Core Technical Details
The reinforcement learning model-driven red teaming mechanism enables Atlas to effectively adapt to new prompt injection tactics. The model simulates attacker behaviors, identifying weaknesses before they can be exploited in the wild. OpenAI’s recognition of intrinsic risks in AI agentic applications suggests a complex balance between advancing capabilities and ensuring security.
Why It Matters for Builders
For developers integrating AI systems into applications, understanding these vulnerabilities is crucial. Implementing proactive security measures will be important to safeguard user interactions and data integrity. The continuous evolution of prompt injection strategies necessitates a landscape-aware approach in design and deployment, pushing builders to adopt robust security frameworks. Failure to do so could expose applications to significant vulnerabilities that could be exploited by malicious actors.
What to Watch / Takeaways
Developers should monitor the effectiveness of OpenAI's automated defenses and how they evolve post-deployment. Key areas to focus on include the adaptability of AI systems to new threats, the implementation of automated penetration testing, and the overall paradigm shift towards security-first design principles in AI technologies. Engaging with the community around these developments could yield valuable insights for fortifying existing systems.